Understanding Diffusion Models - A Mathematical Derivation
Introduction
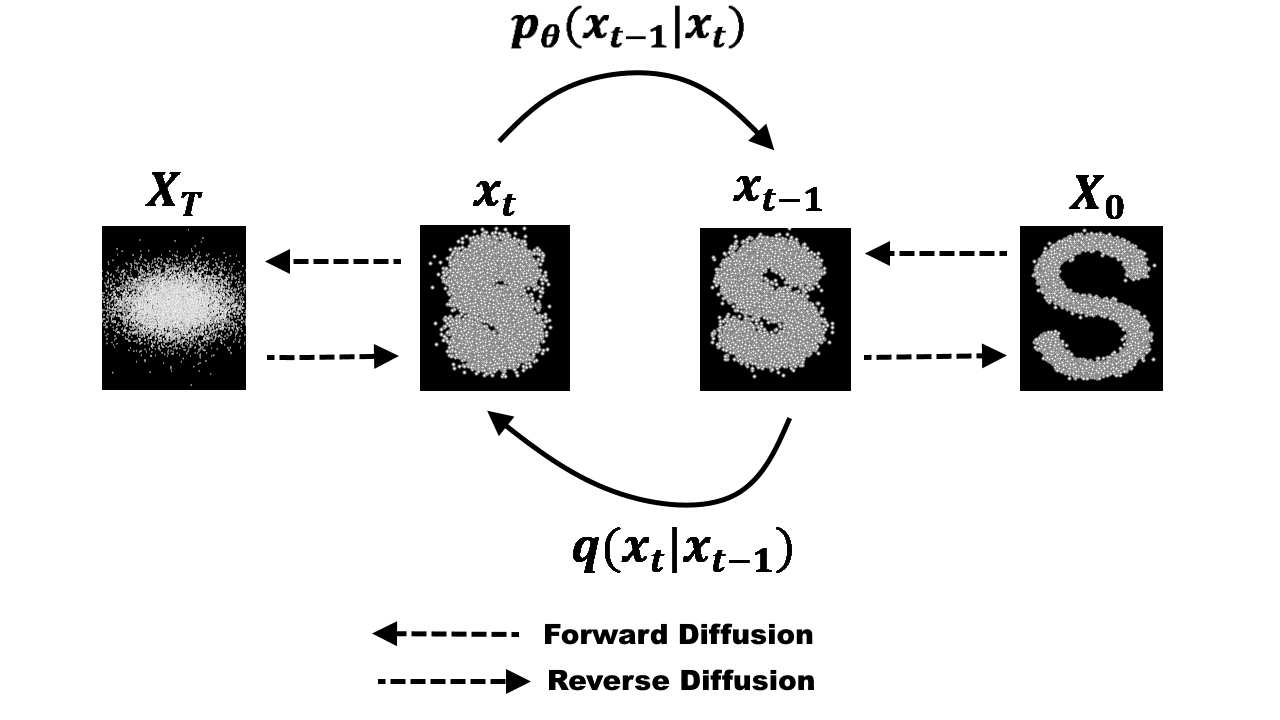
Diffusion models have recently taken the generative AI world by storm, powering state-of-the-art systems like DALL-E 2, Imagen, and Stable Diffusion. Unlike GANs or VAEs, diffusion models work by gradually adding noise to data and then learning to reverse this process.
In this post, we will dive deep into the mathematical foundations of Denoising Diffusion Probabilistic Models (DDPM).
Forward Process (Diffusion)
Main Theory
The forward process, also known as the diffusion process, gradually adds Gaussian noise to a data point
Each step in the forward process is defined as:
where
The formula for adding noise in a single diffusion step is:
This means at each timestep
Although it looks like a step-by-step process, a key property of the forward process is that we can sample
Or equivalently:
Deriving the Weights:
We begin with the recurrence relation for the forward diffusion process:
Each
Step-By-Step Expansion
Let’s compute the first few steps to reveal the pattern, applying the rule of adding normal distributions at each step:
For
: For
: Now we merge the two noise terms
and . Since both and are independent , the combined noise is where: Thus, by writing
, we have: For
:
Following the same logic:Merging the noise terms again:
So, we have:
By induction, we can generalize this pattern for any arbitrary timestep
where
Intuitive Meaning
- Signal Decay: The original image
is gradually “faded out” as it is multiplied by at each step. After steps, the remaining signal is . - Noise Accumulation: Each step adds a new “layer” of random noise. Because these noise layers are independent, they don't just add up linearly; instead, their variances add up, which is why the total noise standard deviation becomes
. - The Diffusion Limit: As
increases towards , approaches 0. This means the original signal eventually vanishes, leaving only pure Gaussian noise.
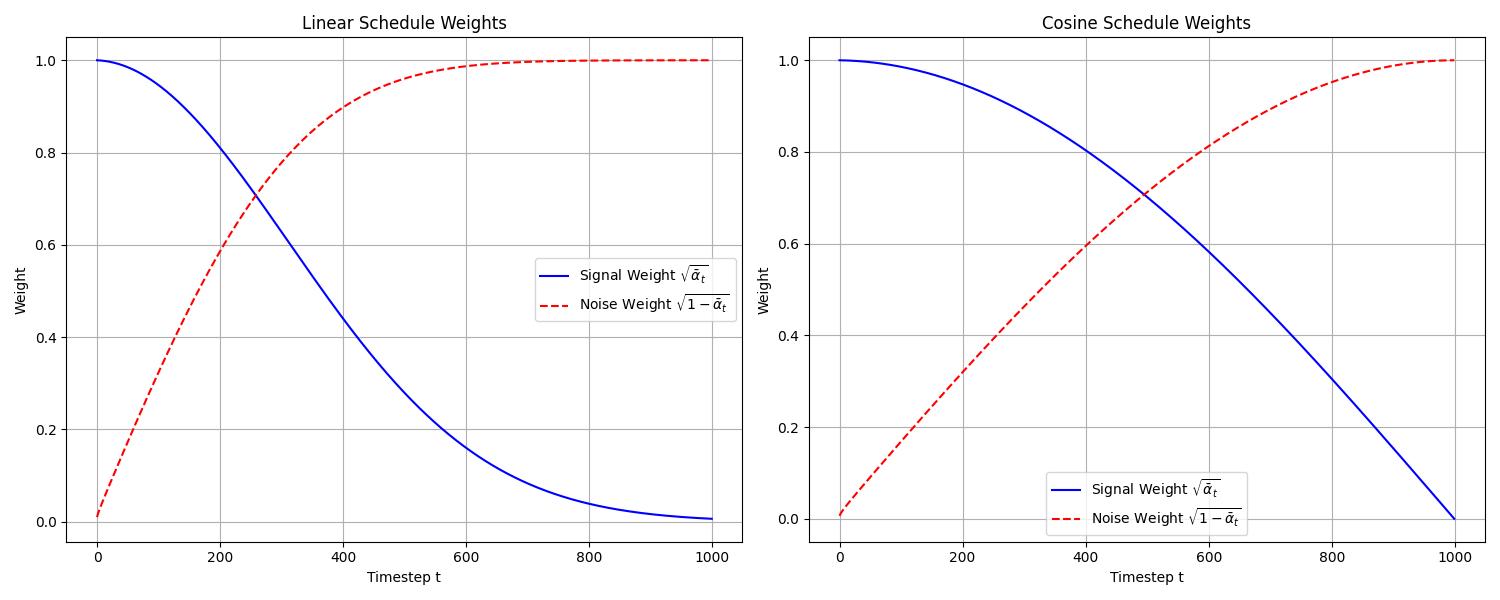
Variance Schedules
The choice of the variance schedule
Linear Schedule
The linear schedule, introduced in the original DDPM paper, defines
While simple, the linear schedule tends to destroy the signal very quickly in the later steps, which can make the reverse process more difficult to learn.
Cosine Schedule
To address the rapid signal decay of the linear schedule, the cosine schedule was proposed in “Improved Denoising Diffusion Probabilistic Models”. It defines
where
The following plots compare the signal weight (
Reverse Process (Generative)
The goal of a diffusion model is to reverse the forward process. If we can successfully sample backwards from
Using Bayes' formula, the expression of the true reverse conditional probability
This is intractable (impossible to compute directly) because the expression of
where the distribution of all real images in the world
To solve this, we train a neural network
Our main challenge now is: how do we find the training target for the network's predicted mean
The Mathematical Trick: Conditioning on
Although
Using Bayes' rule, we can rewrite this conditional probability as:
Notice that every single term on the right side of the equation is a forward process probability that we already defined in the previous section.
is just the standard one-step forward transition , which is . is the “shortcut” transitions that let us jump directly from , which is . is similar to above, which is .
The probability density function (PDF) of normal distribution is
Multiplying these Gaussian densities together, the exponent part of
We want the exponent to be in the form of this:
Derive Expression of
Since
Constant can be removed from the exponent because
Expand everything and combine:
Now we have this form in the exponent:
where
After removing
So:
Take the inverse:
Similarly:
Finally, we find that
Making Sense of the Ground-Truth Mean
Don't be intimidated by these heavy coefficients! The physical meaning of
- The current noisy image
. - The final clean image
.
Shifting from Image Predictor to Noise Predictor
Ideally, we want our neural network's
To bypass this, we use the forward shortcut formula we derived earlier to express
If we substitute this definition of
Look at this elegant result! The only unknown variable left in this ground-truth mean is
This reveals the core breakthrough of the DDPM paper: instead of training the neural network to predict the entire complex image mean
Sampling Process (Inference)
Basic
Now that our neural network
We start from pure Gaussian noise
At each reverse step, we want to sample
Using the mathematical breakthrough we derived in the previous section, we can parameterize the network's predicted mean
For the standard deviation
We sample a random noise vector
Note on the final step: When
, we are generating the final clean image . At this last step, we no longer add random noise, so we set to get the clean deterministic output.
Practical Implementation
Using the sampling process above, the result will be unstable. This is mainly caused by the
When the sampling process starts, the first
Besides, the value of the
Therefore, we will do the following sampling steps.
First, approximate the clean image by the predicted noise:
Then clip the value to a valid range (usually
Finally, inject the clipped predicted clean image back to the original mean formula to get a more stable result.
Conclusion
The genius of DDPM lies in avoiding the direct calculation of the intractable real data distribution
By shifting the training objective from “predicting a perfect clean image” to “predicting a standard normal noise vector
With these foundational math formulas locked down, we are now fully equipped to implement this elegant system in PyTorch from scratch!
- Title: Understanding Diffusion Models - A Mathematical Derivation
- Author: Fireflies
- Created at : 2026-05-21 15:44:15
- Updated at : 2026-07-08 07:17:24
- Link: https://fireflies3072.github.io/diffusion-model/
- License: This work is licensed under CC BY-NC-SA 4.0.